Systems Resource Requirement Analysis
In this experiment, we reproduce the systems analysis experiment conducted in the LEAF paper.
Specifically, we identify the systems budget (in terms of compute [number of FLOPs]
and network bandwidth) required when training with minibatch SGD vs. FedAvg, using the LEAF framework.
For this example, we shall use the FEMNIST dataset to perform an image classification task using a 2-layer convolutional neural network.
Experiment Setup and Execution¶
For this experiment, we describe how to use the LEAF framework to execute minibatch SGD for 3 clients with a 10% batch-size.
Quickstart script¶
In the interest of ease of use, we provide a script for execution of the experiment
for different settings for SGD and FedAvg, which may be executed as:
leaf/paper_experiments $> ./femnist.sh <result-output-dir>
This script will execute the instructions provided using both minibatch SGD and FedAvg for different configurations of clients per round, batch size and local epochs, reproducibly generating the data partitions and results observed by the authors during analysis.
Dataset fetching and pre-processing¶
LEAF contains powerful scripts for fetching and conversion of data into JSON format for easy utilization. Additionally, these scripts are also capable of subsampling from the dataset, and splitting the dataset into training and testing sets.
For our experiment, as a first step, we shall use 5% of the dataset in an 80-20 train/test split. The following command shows
how this can be accomplished (the --spltseed and --smplseed flags in this case is to enable reproducible generation of the dataset)
leaf/data/femnist/ $> ./preprocess.sh -s niid --sf 0.05 -k 0 -t sample --smplseed 1549786595 --spltseed 1549786796
After running this script, the data/femnist/data directory should contain train/ and test/ directories.
Model Execution¶
Now that we have our data, we can execute our model! For this experiment, the model file is stored
at models/femnist/cnn.py. In order train this model using SGD with 3 clients per round
and 10% batch size, we execute the following command:
leaf/models $> python main.py -dataset femnist -model cnn -lr 0.06 --minibatch 0.1 --clients-per-round 3 --num-rounds 2000
Metrics Collection¶
Executing the above command will write out system and statistical metrics to leaf/models/metrics/stat_metrics.csv and leaf/models/metrics/sys_metrics.csv - since these are overwritten for every run, we highly recommend storing the generated metrics files at a different location.
To experiment with a different configuration, re-run the main model script with a different flags. The plots shown below can be generated using plots.py file in the repo root.
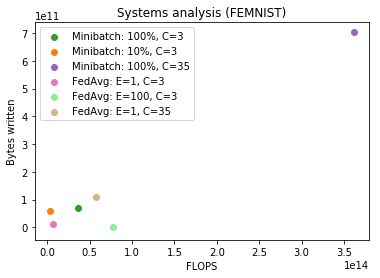
Results and Analysis¶
For an accuracy threshold of 75%, we see an improved systems profile of FedAvg when it comes to the communication vs. local computation trade-off, though we note that in general methods may vary across these two dimensions, and it is thus important to consider both aspects depending on the problem at hand.
More Information¶
More information about the framework, challenges and experiments can be found in the LEAF paper.